S3 Ingestion
S3 Ingestion lets you pull files from Amazon S3 or S3-compatible storage (MinIO, NCP Object Storage, etc.) directly into your AI Data Foundry project.
After connecting a source, use Import now to ingest files immediately, or set up an automatic schedule to periodically collect newly added files.
Prerequisites
You will need the following information to connect an S3 source.
| Item | Description |
|---|---|
| Bucket name | The name of the S3 bucket where files are stored (e.g., my-documents-bucket) |
| Region | The AWS region where the bucket is located (e.g., ap-northeast-2). The form defaults to ap-northeast-2 — change it to match your actual bucket region |
| Access Key ID | Access Key ID of an IAM user with access to the S3 bucket |
| Secret Access Key | The Secret Access Key corresponding to the Access Key above |
IAM Permissions
The IAM user used for the connection needs at least the following permissions.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:HeadBucket",
"s3:ListBucket",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::my-documents-bucket",
"arn:aws:s3:::my-documents-bucket/*"
]
}
]
}Replace
my-documents-bucketwith your actual bucket name.
s3:HeadBucket— Verifies the bucket exists during connection tests3:ListBucket— Lists files and folders in the buckets3:GetObject— Downloads files during ingestion
Step 1: Connect an S3 Source
Click the Ingestion tab in the left sidebar.
Click Connect a new source.

Select Amazon S3 as the source type and fill in the fields.
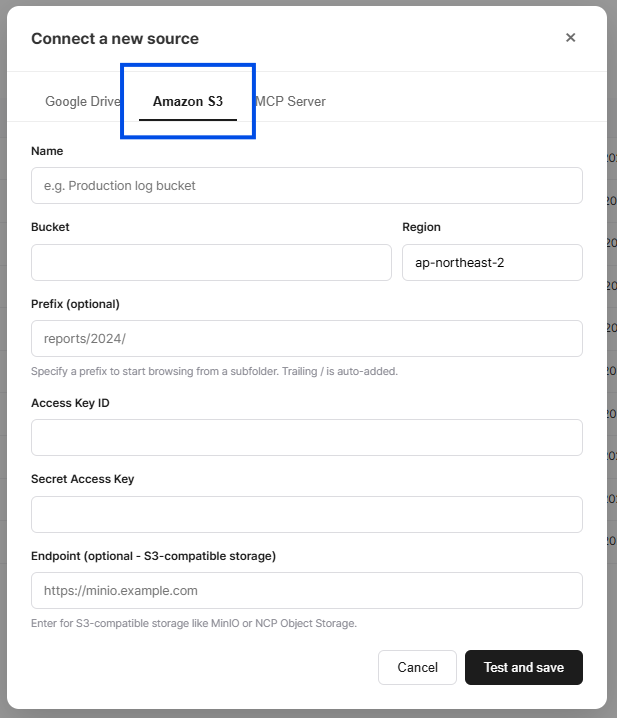
| Field | Required | Description |
|---|---|---|
| Name | Yes | A friendly name for this source (e.g., "Production log bucket") |
| Bucket | Yes | S3 bucket name |
| Region | Yes | AWS region (form default: ap-northeast-2 — change to match your bucket) |
| Prefix | No | Start browsing from a specific folder (e.g., reports/2026/). A trailing / is automatically appended |
| Access Key ID | Yes | IAM Access Key ID |
| Secret Access Key | Yes | IAM Secret Access Key |
| Endpoint | No | Only needed for S3-compatible storage |
Click Test and save to automatically test that the bucket is accessible.
If the test passes, the source is registered and a source card appears.

Credentials are encrypted before storage and are never included in API responses.
Step 2: Ingest Files
Once the source is connected, you can pull files from the bucket into your project.
Click Import now on the source card to scan the entire bucket and automatically ingest eligible files.
How Ingestion Works
- First run: Scans and ingests all files within the bucket (or Prefix scope).
- Subsequent runs: Only files added or modified since the last ingestion are collected (incremental ingestion).
- Deduplication: Files already ingested from the same source are not imported again.
- Per-run limit: Scheduled (automatic) runs process up to 200 files per run; manual (Import now) runs process up to 50 files per run. Any remaining files will be picked up in the next run.
Progress is shown in real time in the Recent ingestion jobs section at the bottom of the page.
Supported Formats and Size Limits
- Formats: All file formats supported by the project (Supported Formats)
- Size: Up to 100 MB per file
Step 3: Set Up Automatic Schedule (Optional)
To automatically ingest new files on a recurring basis, enable a schedule.
- Click the Run schedule dropdown on the source card.
- Choose your preferred interval:
| Interval | Description |
|---|---|
| Manual only | No automatic ingestion (default) |
| Every 6 hours | Automatically ingest new files every 6 hours |
| Every 12 hours | Automatically ingest new files every 12 hours |
| Every day | Automatically ingest new files every 24 hours |
| Every week | Automatically ingest new files every 7 days |
- The schedule is activated as soon as you select an interval.
Once the schedule is active, the source card displays the Last run time and Next run estimate.
Run Now
Click Import now at any time to trigger an immediate ingestion without waiting for the next scheduled cycle.
Monitoring Ingestion Jobs
The Recent ingestion jobs table at the bottom of the Ingestion page shows the history of all ingestion jobs.
| Column | Description |
|---|---|
| Source | Which source the files were ingested from |
| Mode | Manual or Scheduled |
| Status | Pending / Running / Completed / Partial / Failed |
| Success / Fail | Number of successfully ingested files and failed files |
| Started / Completed | Job start and completion timestamps |
Click a job row to view the detailed list of ingested files.
Status Reference
| Status | Meaning |
|---|---|
| Pending | The job is queued and waiting to be processed |
| Running | Files are being downloaded and imported into the project |
| Completed | All files were successfully ingested |
| Partial | Some files succeeded, some failed (unsupported format, size exceeded, etc.) |
| Failed | The entire job failed (connection error, etc.) |
Connecting S3-Compatible Storage
In addition to Amazon S3, any storage that provides an S3-compatible API can be connected in the same way.
How to Connect
Enter the storage endpoint URL in the Endpoint field when connecting a source.
| Storage | Endpoint Example |
|---|---|
| MinIO (local) | http://localhost:9000 |
| NCP Object Storage | https://kr.object.ncloudstorage.com |
| Cloudflare R2 | https://{account_id}.r2.cloudflarestorage.com |
All other fields (Bucket, Region, Access Key ID, Secret Access Key) should be filled with the values provided by the respective storage service.
When an Endpoint is provided, Path Style access is automatically enabled. No additional configuration is needed.
FAQ
Connection to the source fails
- Verify that the IAM user has the
s3:HeadBucketpermission. - Double-check that the bucket name and region are correct.
- For S3-compatible storage, make sure the Endpoint URL is valid.
Ingested files do not appear in the project
- Check that the ingestion job status is Completed.
- If you specified a target folder, look for the files in that folder.
- Verify that the file format is included in Supported Formats.
Files are missing from ingestion
- After the first run, ingestion only fetches files modified since the last run. Previously existing but unmodified files are not included.
- There is a per-run limit on the number of files processed: up to 200 for scheduled (automatic) runs and up to 50 for manual (Import now) runs. Excess files will be picked up in the next run.
- Files already ingested (same source + same file path) are skipped by deduplication.
Will deleting a source also delete already ingested files?
No. Deleting a source only removes the connection configuration and schedule settings. Files already imported into your project remain untouched.